Recently, I got a question on a mixed model with highly correlated random slopes. I requested a copy of the data because it is much easier to diagnose the problem when you have the actual data. The data owner gave permission to use an anonymised version of the data for this blog post. In this blog post, I will discuss how I’d tackle this problem.
Data exploration
Every data analysis should start with some data exploration. The dataset contains three variables: the response \(Y\), a covariate \(X\) and a grouping variable \(ID\).
Y X ID
Min. : 40.05 Min. :1.054 Min. : 1.0
1st Qu.: 72.25 1st Qu.:1.397 1st Qu.:148.0
Median : 88.99 Median :1.563 Median :273.0
Mean : 99.34 Mean :1.669 Mean :286.9
3rd Qu.:115.92 3rd Qu.:1.836 3rd Qu.:434.0
Max. :351.49 Max. :4.220 Max. :601.0
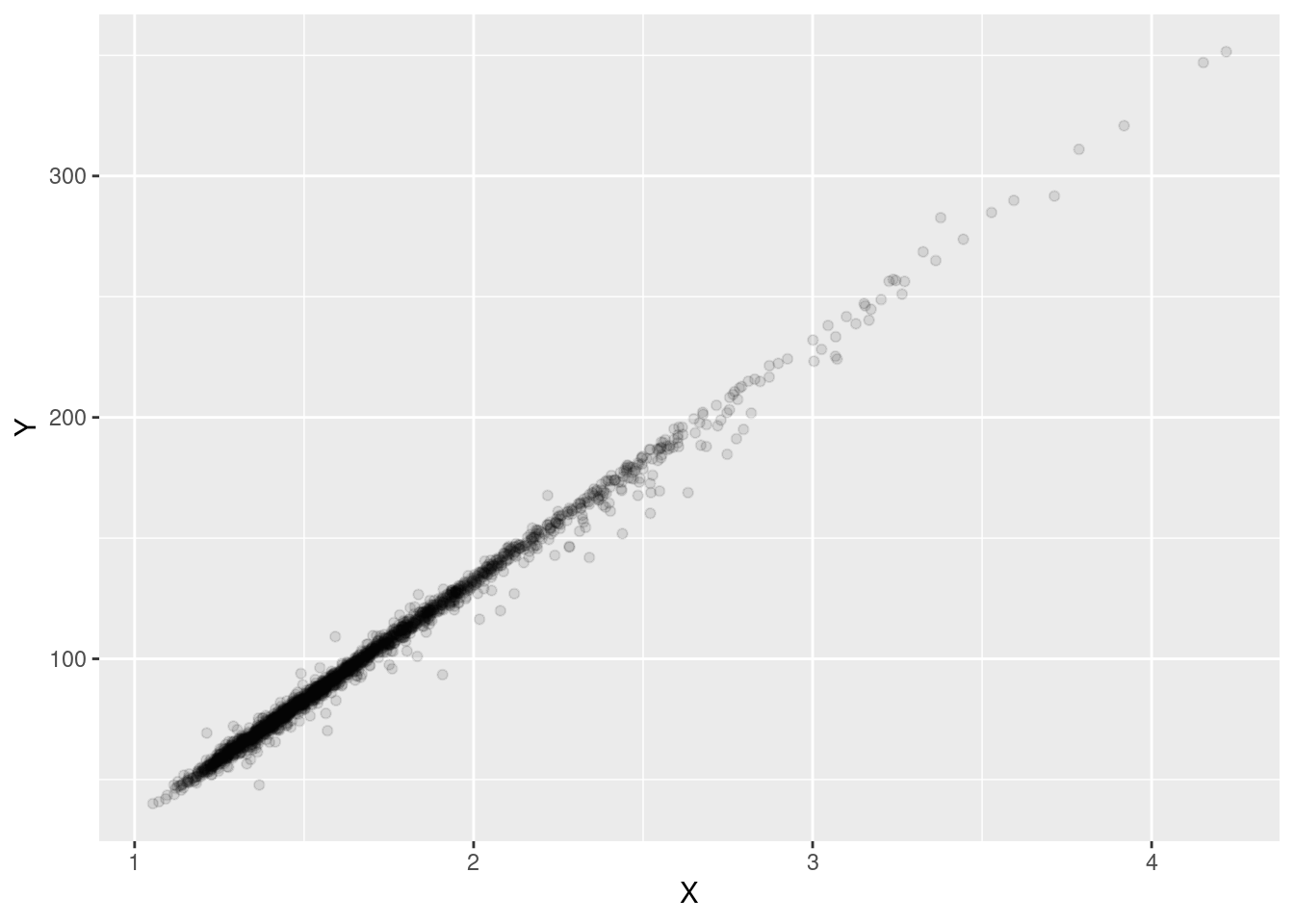
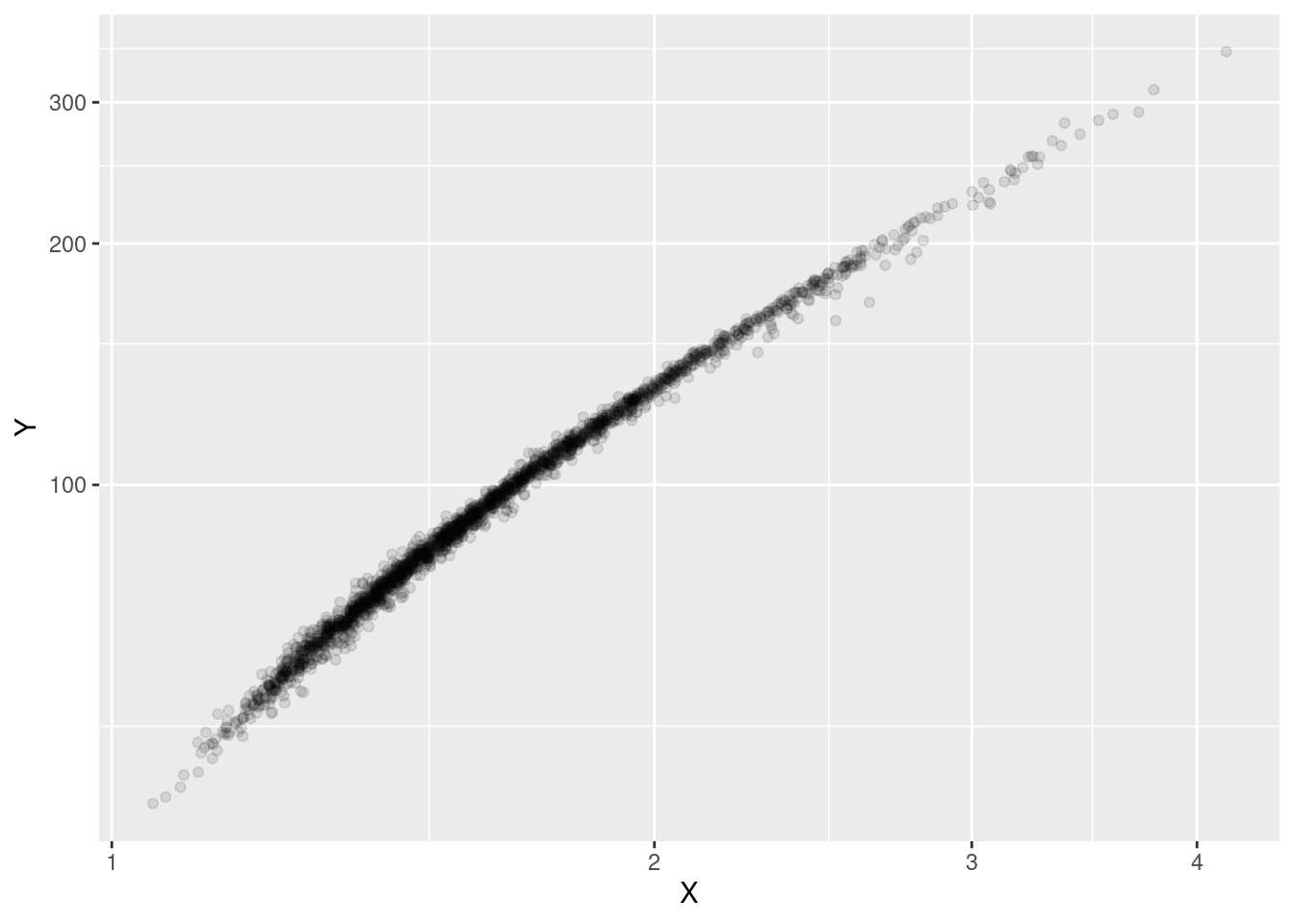
Let’s start by looking at a scatter plot (Figure 1). This suggests a strong linear relation between \(X\) and \(Y\). Plotting the point with transparency reveals that the density of the observations depends on the value. This is confirmed by the skewed distribution shown in Figure 2. This is something we have to keep in mind.
ggplot(dataset, aes(x = X, y = Y)) +geom_point(alpha =0.1)
The mathematical equation of the random slope model is given in Equation 1. It contains a fixed intercept and fixed slope along \(X\) and a random intercept and random slope along \(X\) for each \(ID\). The random intercept \(b_{0i}\) and random slope stem \(b_{1i}\) from a bivariate normal distribution.
The number of groups and the number of observations per group are two important things to check before running a mixed model. Figure 3 indicates that there are plenty of groups but a large number of groups have only one or just a few observations. This is often problematic in combination with a random slope. Let’s see what the random slope actually does by cutting some corners and simplifying the mixed model into a set of hierarchical linear models. We have one linear model ‘FE’ that fits the response using only the fixed effects. For each group we fit another linear model on the residuals of model ‘FE’. So when there are only two observations in a group, the random slope model fits a straight line through only two points… To make things even worse, many groups have quite a small span (Figure 4). Image the worst case were a group has only two observations, both have extreme and opposite residuals from model ‘FE’ and their span is small. The result will be an extreme random slope…
Figure 4: Density of the span (difference between min and max) for all groups with at least 2 observations
Original model
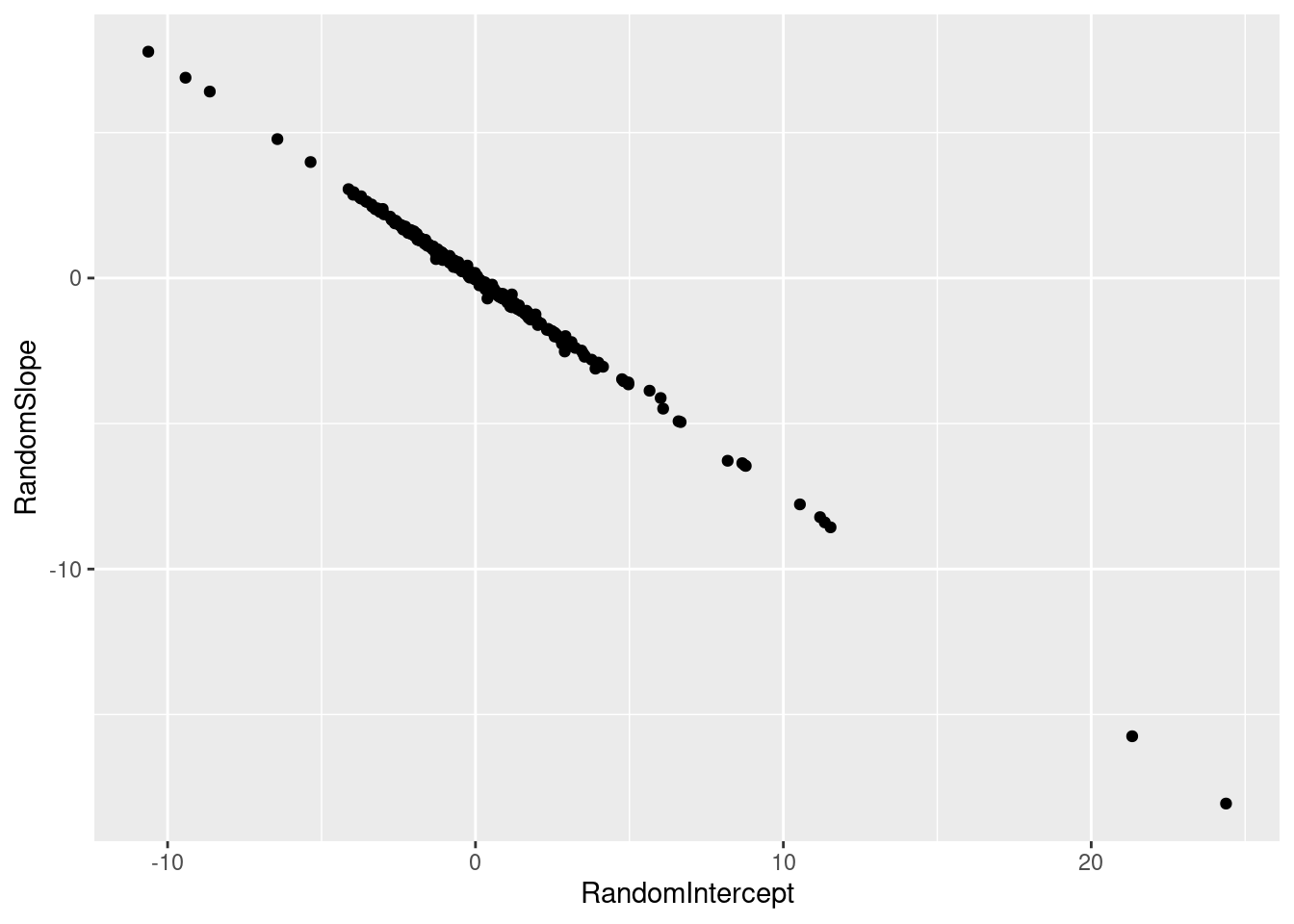
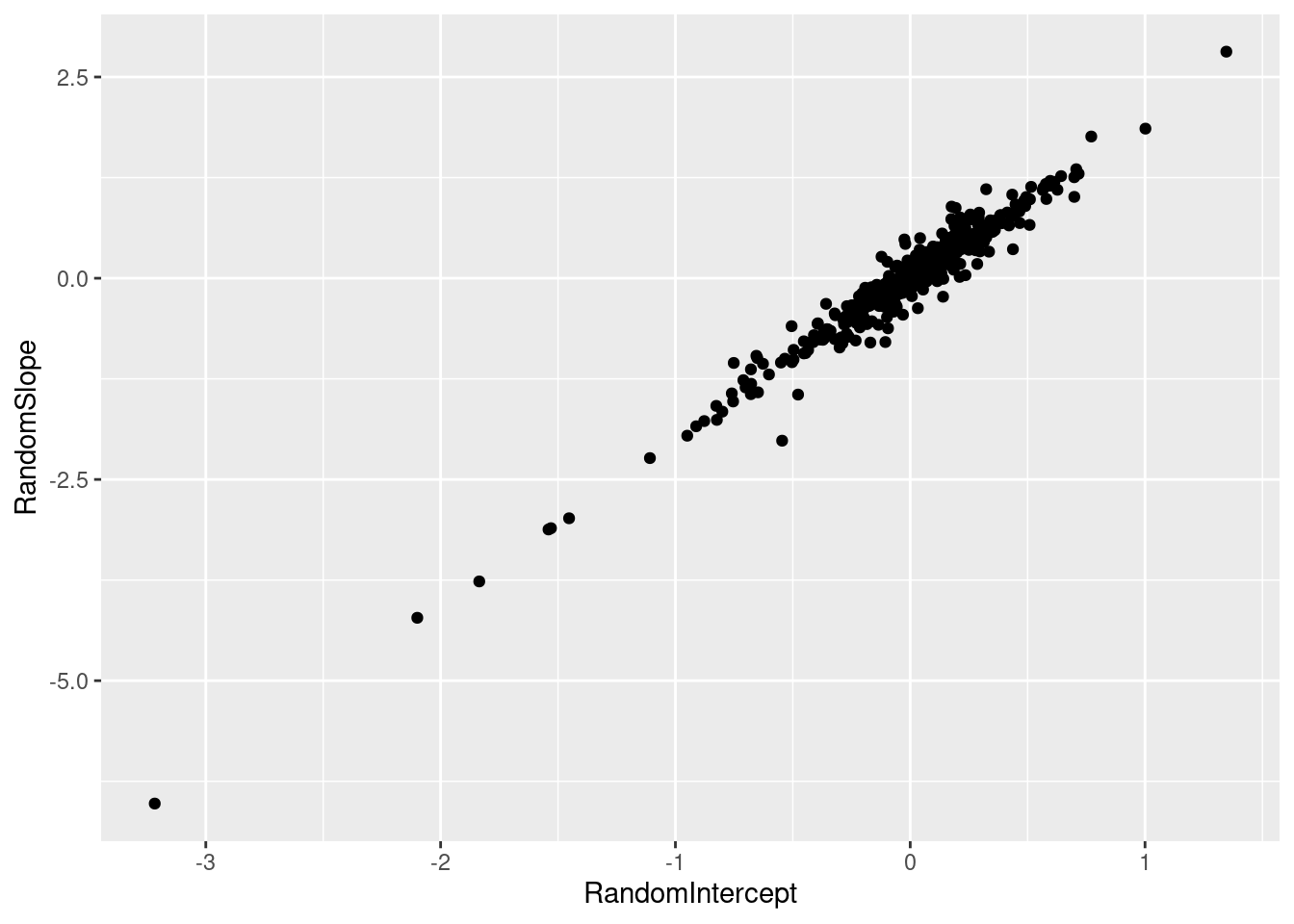
First we fit the original model. Notice the perfect negative correlation between the random intercept and the random slope. This triggered, rightly, an alarm with the researcher. The perfect correlation is clear when looking at a scatter plot of the random intercepts and random slopes (Figure 5). Figure 6 show the nine most extreme random slopes. The Y-axis displays the difference between the observed \(Y\) and the model fit using only the fixed effects (\(\beta_0 + \beta_1X\)). Note that the random slopes are not as strong as what we would expect from the naive hierarchical model we described above. Mixed models apply shrinkage to the coefficients of the random effects, making them less extreme.
model <-lmer(Y ~ X + (X | ID), data = dataset)summary(model)
Linear mixed model fit by REML ['lmerMod']
Formula: Y ~ X + (X | ID)
Data: dataset
REML criterion at convergence: 10753.1
Scaled residuals:
Min 1Q Median 3Q Max
-8.6576 -0.3511 0.0692 0.4535 6.5774
Random effects:
Groups Name Variance Std.Dev. Corr
ID (Intercept) 21.050 4.588
X 11.102 3.332 -1.00
Residual 6.124 2.475
Number of obs: 2234, groups: ID, 601
Fixed effects:
Estimate Std. Error t value
(Intercept) -64.3591 0.4219 -152.6
X 98.0603 0.2783 352.4
Correlation of Fixed Effects:
(Intr)
X -0.986
Figure 6: Illustration of the most extreme random slopes.
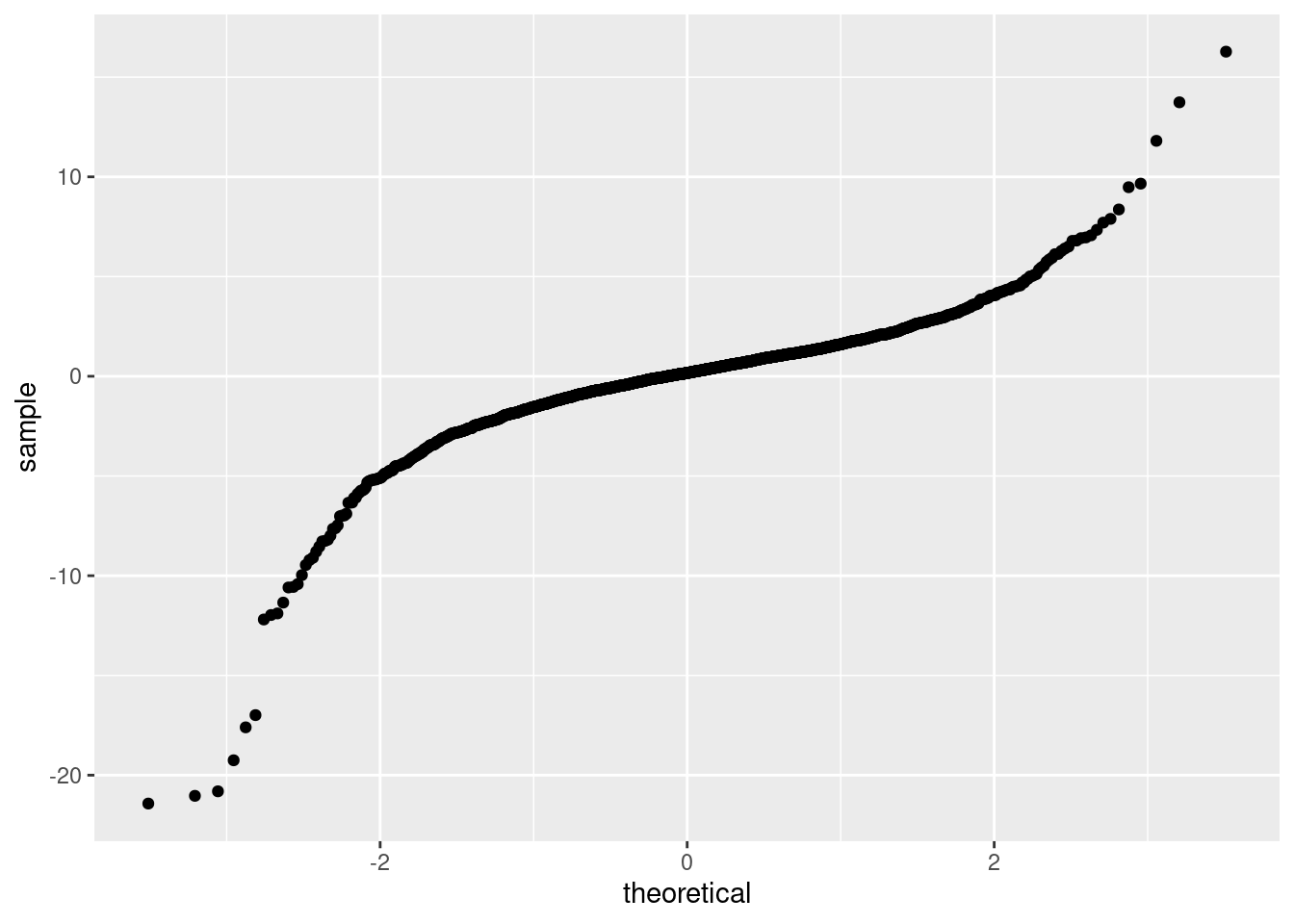
Until now, we focused mainly on the random effects. Another thing one must check are the residuals. The QQ-plot (Figure 7) indicates that several observations have quite strong residuals. Those should be checked by an expert with domain knowledge on the data. I recommend to start by looking at the top 20 observations with the most extreme residuals. Question the data for these observations: e.g. was the measurement correct, was the data entry correct, … When the data turns out to be OK, question it’s relevance for the model (e.g. is the observation a special case) and question the model itself (e.g. are missing something important in the model, does the model makes sense). Refit the model after the data cleaning and repeat the process until you are happy with both the model and the data.
ggplot(dataset, aes(sample = Resid)) +stat_qq()
Figure 7: Density of the residuals
Potential solutions
Removing questionable observations
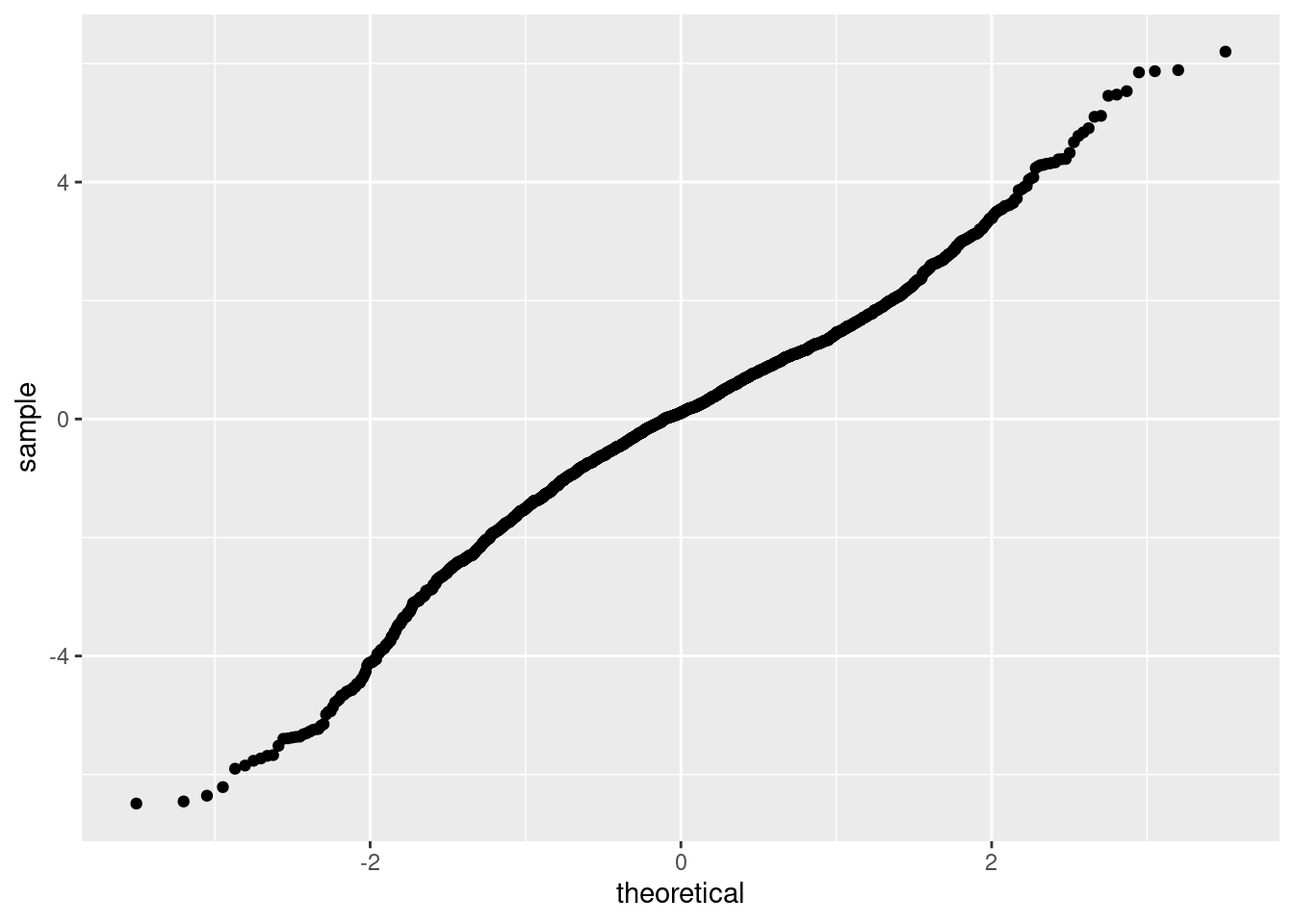
Here we demonstrate what happens in case all observations with strong residuals turn out to be questionable and are removed from the data. Note that we do not recommend to simply remove all observation with strong residuals. Instead have a domain expert scrutinise each observation and remove only those observations which are plain wrong or not relevant. This is something I can’t do in this case because I don’t have the required domain knowledge. For demonstration purposes I’ve removed all observations who’s residuals are outside the (0.5%, 99.5%) quantile of the theoretical distribution of the residuals. The QQ-plot (fig. @ref(fig:qq-cleaned)) now looks OK, but we still have perfect correlation among the random effects.
dataset_cleaned <- dataset %>%filter(abs(Resid) <qnorm(0.995, mean =0, sd =sigma(model)))model_cleaned <-lmer(Y ~ X + (X | ID), data = dataset_cleaned)summary(model_cleaned)
Linear mixed model fit by REML ['lmerMod']
Formula: Y ~ X + (X | ID)
Data: dataset_cleaned
REML criterion at convergence: 9182.5
Scaled residuals:
Min 1Q Median 3Q Max
-3.6053 -0.4946 0.0577 0.5772 3.4444
Random effects:
Groups Name Variance Std.Dev. Corr
ID (Intercept) 20.973 4.580
X 9.500 3.082 -1.00
Residual 3.241 1.800
Number of obs: 2188, groups: ID, 598
Fixed effects:
Estimate Std. Error t value
(Intercept) -64.6873 0.3471 -186.3
X 98.3516 0.2257 435.7
Correlation of Fixed Effects:
(Intr)
X -0.989
Figure 8: QQ-plot for the original model on the cleaned dataset.
Centring and scaling
Another thing that often can help is centring and scaling the data. In this case we centre to a zero mean and scale to a standard deviation of 1. Personally I prefer to centre to some meaningful value in the data. E.g. when the variable is the year of the observation I would centre to the first year, last year or some other important year within the dataset. This makes the interpretation of the model parameters easier. I usually scale variables by some power of 10 again because of the interpretation of the parameters.
We will keep using the cleaned dataset so that the problematic observation don’t interfere with the effect of centring and scaling. Scaling improves the correlation between the random intercept and the random slope. It is no longer a perfect correlation but still quite strong (Figure 9). Note that the sign of the correlation has changed. Although we removed the questionable observations, there are still some groups of observations with quite strong deviations from the fixed effects part from the model (Figure 10).
dataset_cleaned <- dataset_cleaned %>%mutate(Xcs =scale(X, center =TRUE, scale =TRUE) )model_centered <-lmer(Y ~ X + (Xcs | ID), data = dataset_cleaned)summary(model_centered)
Linear mixed model fit by REML ['lmerMod']
Formula: Y ~ X + (Xcs | ID)
Data: dataset_cleaned
REML criterion at convergence: 9182.5
Scaled residuals:
Min 1Q Median 3Q Max
-3.6053 -0.4946 0.0577 0.5772 3.4444
Random effects:
Groups Name Variance Std.Dev. Corr
ID (Intercept) 0.3996 0.6322
Xcs 1.4161 1.1900 0.88
Residual 3.2413 1.8004
Number of obs: 2188, groups: ID, 598
Fixed effects:
Estimate Std. Error t value
(Intercept) -64.6873 0.3471 -186.4
X 98.3516 0.2257 435.7
Correlation of Fixed Effects:
(Intr)
X -0.989
Figure 10: Illustration of the most extreme random slopes after centering and scaling.
Simplifying the model
Based on Figure 3 and Figure 4 we already concluded that a random slope might be pushing it for this data set. So an obvious solution is to remove the random slope and only keep the random intercept. Though there still are quite a large number of groups with only one observation (Figure 3), this is often less problematic in case you have plenty of groups with multiple observations. Note that the variance of the random intercept of this model is much smaller than in the previous models. The random intercept model is not as good as the random slope model in terms of AIC, but this comparison is a bit pointless since the random slope model is not trustworthy.
model_simple <-lmer(Y ~ X + (1| ID), data = dataset_cleaned)summary(model_simple)
Linear mixed model fit by REML ['lmerMod']
Formula: Y ~ X + (1 | ID)
Data: dataset_cleaned
REML criterion at convergence: 9593.6
Scaled residuals:
Min 1Q Median 3Q Max
-6.2261 -0.4503 0.0682 0.5238 6.0184
Random effects:
Groups Name Variance Std.Dev.
ID (Intercept) 1.897 1.377
Residual 3.688 1.921
Number of obs: 2188, groups: ID, 598
Fixed effects:
Estimate Std. Error t value
(Intercept) -64.1588 0.2736 -234.5
X 97.9788 0.1572 623.2
Correlation of Fixed Effects:
(Intr)
X -0.959
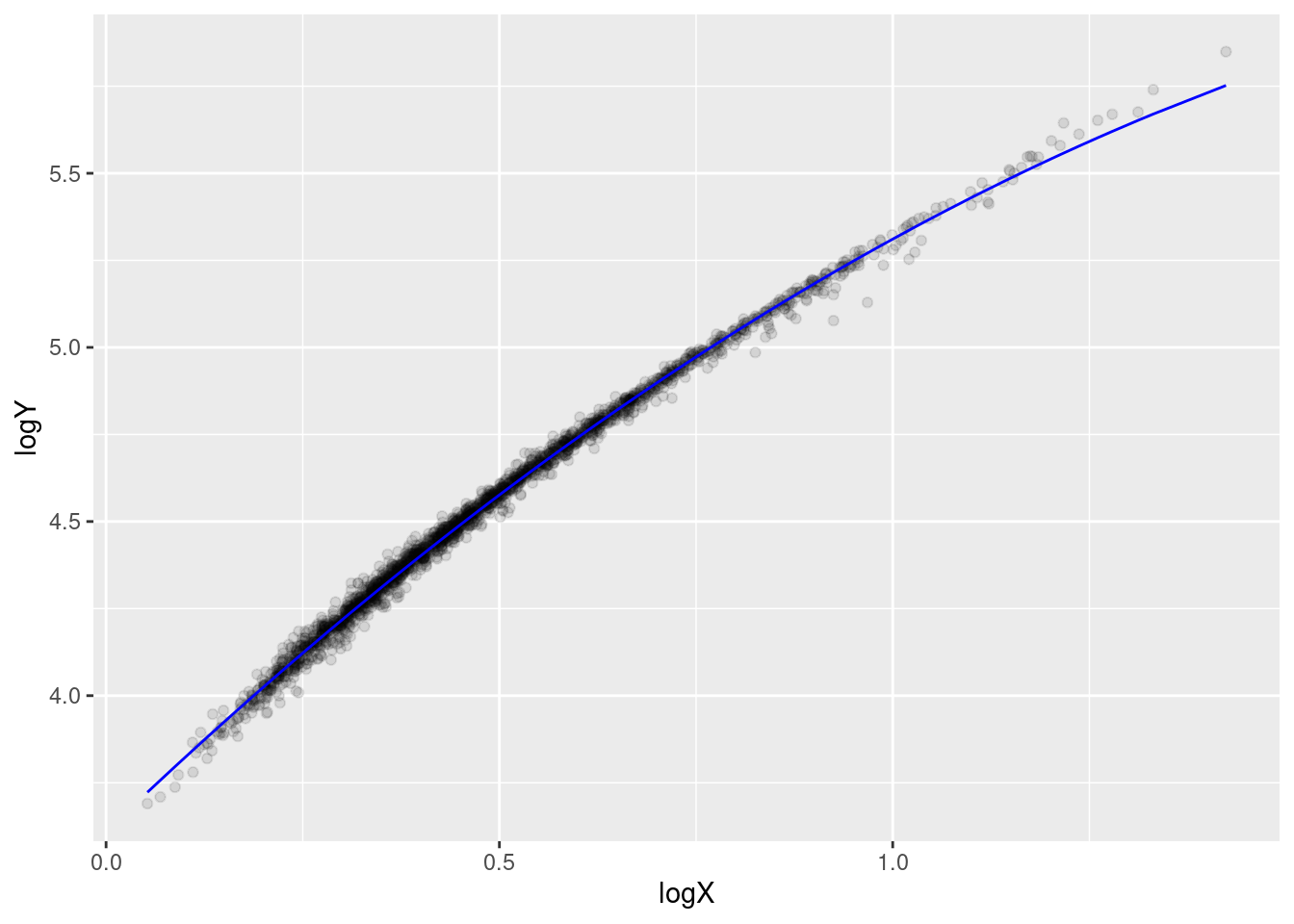
Figure 2 indicated that the distribution of both \(X\) and \(Y\) is quite skewed. A \(log\)-transformation reduces the skewness (Figure 11) and reveals a quadratic relation between \(\log(X)\) and \(\log(Y)\) (Figure 12).
Figure 11: Density of \(X\) and \(Y\) after log-transformation
ggplot(dataset_cleaned, aes(x = X, y = Y)) +geom_point(alpha =0.1) +coord_trans(x ="log", y ="log")
Figure 12: Scatterplot after log-transformation.
This might be a relevant transformation, but it needs to be checked by a domain expert because this random slope model Equation 2 expresses a different relation between \(X\) and \(Y\). The fixed part of model Equation 2 becomes \(Y \sim e^{\gamma_0 }X^{\gamma_1}\) after back transformation.
Linear mixed model fit by REML ['lmerMod']
Formula: logY ~ logX + (1 | ID)
Data: dataset_cleaned
REML criterion at convergence: -8723.6
Scaled residuals:
Min 1Q Median 3Q Max
-6.3306 -0.4654 0.1075 0.5517 2.8275
Random effects:
Groups Name Variance Std.Dev.
ID (Intercept) 0.0006140 0.02478
Residual 0.0007947 0.02819
Number of obs: 2188, groups: ID, 598
Fixed effects:
Estimate Std. Error t value
(Intercept) 3.747007 0.002623 1428.6
logX 1.612781 0.004681 344.5
Correlation of Fixed Effects:
(Intr)
logX -0.871
A quadratic fixed effect of \(\log(X)\) improves the model a lot. The resulting fit is given in Figure 13.